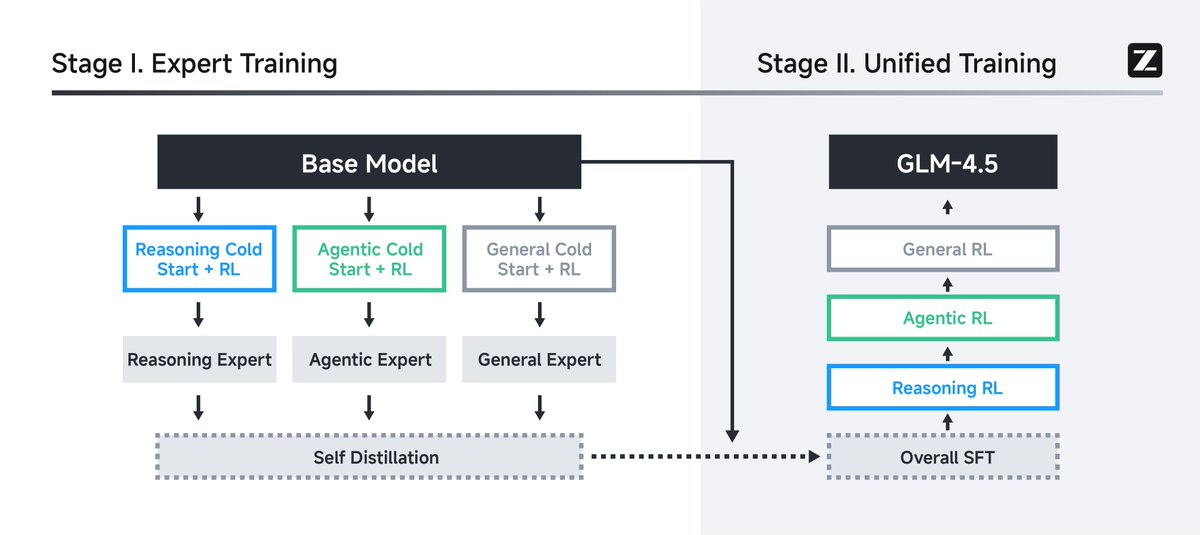
o3 competitor: GLM 4.5 by Zhipu AI
- hybrid reasoning model (on by default)
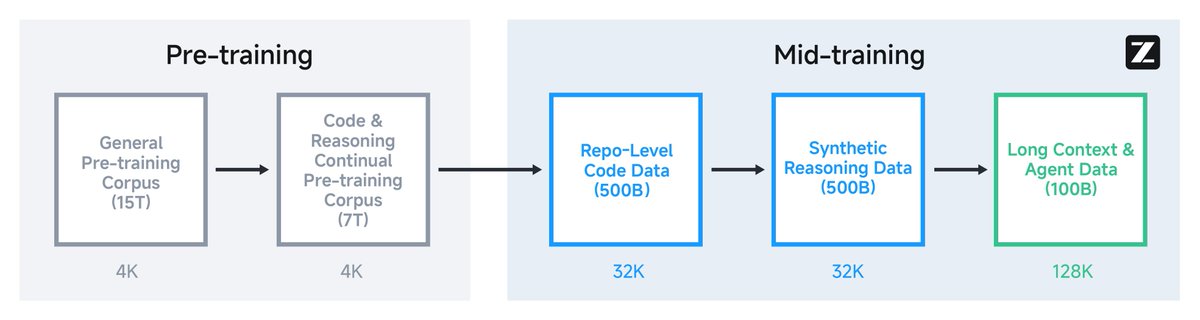
- trained on 15T tokens
- 128k context, 96k output tokens
- $0.11 / 1M tokens
- MoE: 355B A32B and 106B A12B
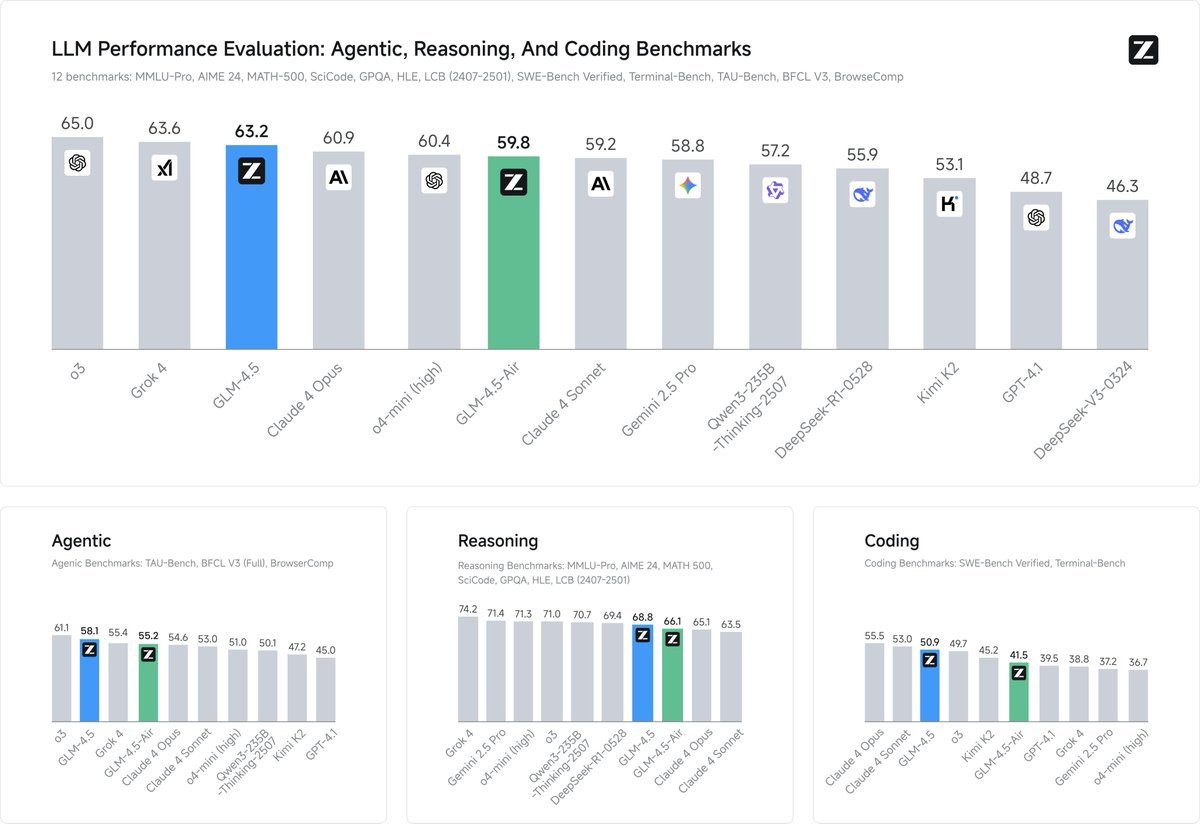
Benchmark details:
- tool calling: 90.6% success rate vs Sonnet’s 89.5% vs Kimi K2 86.2%
- coding: 40.4% win rate vs Sonnet, 53.9% vs Kimi K2, 80.8% vs Qwen3 Coder
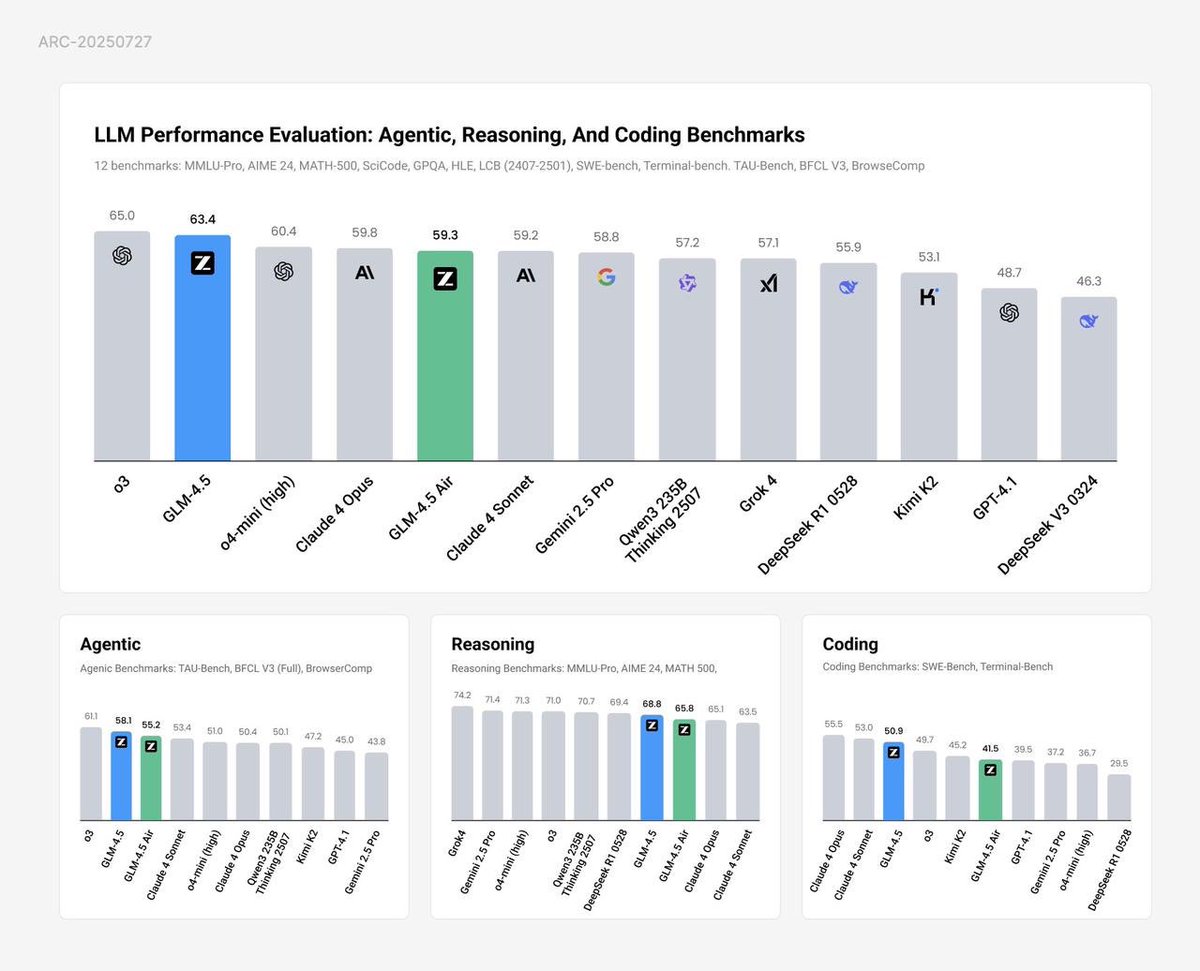
Update: Zhipu AI says the initial benchmark I posted are not up-to-date, so here is the updated version.
Note that I found the original benchmark comparison on their bigmodel documentation. https://t.co/E0PBaF9Kti